

Why Are LLMs Already On A Race To The Bottom?
And What Can This Teach You About Positioning Your Product?

(Note: This post first appeared as a guest post for The Gen AI Collective, the largest community of AI enthusiasts in San Francisco, with over 10,000 members. I founded and run the Marin & Sonoma chapter of the Gen AI Collective and am grateful to Eric Fett and
for the opportunity to collaborate on this.)
Only twice in my adult life has trying a new tech product taken my breath away.
The first was when I unboxed my first-generation iPhone on the day of release. The second was the first time I used Chat GPT.
But though the pace of advancement for AI is faster, it is smartphones that have managed to increase in price over time, while LLM pricing seems headed for zero.
What’s going on here?
How did the most exponential technology in history get reduced to a commodity in the space of just 18 months?
And if it can happen to the titans of LLM creation, with all their talent and money, what does it mean for you and your AI product?
Let’s have a look at one specific factor: positioning.
The Irresistible Pull of Comparison
There have been many great articles recently about the importance of positioning your product as different, not just better and avoiding competition. Check out this from
, this from , this from or this from myself, to cite just a few.These articles argue is that most entrepreneurs default to “competing” without even thinking about it. I’d add that this bias is matched by a habit of the customer to compare.
Even if you try not to engage in the comparison game, you will be sucked into it.
This a problem because product comparison always happens on a continuum of price vs some other feature. As I explain in my recent article Category Proof in Engineering, the extent to which you are “better” limits the extent to which you can charge more. And when your competitors reduce their prices, or raise their quality to reduce your leadership, your margins get pulled down with it.
The Cost of Comparison
Lack of pricing power is especially problematic for LLMs because of the massive costs involved in scaling compute, training, and talent.
And yet, just 18 months since the world marveled at the release of ChatGPT, head-to-head comparison of features, capabilities, and pricing is the status quo for all LLMs.
The many leaderboards are emblematic of this.
Death By Leaderboard
The default state of customers and analysts is to compare, but we’re currently seeing a new SOTA model being released several times per week, which makes it hard for market commentators to keep track, and hard for prospective buyers to choose.
There are various established comparison methods like MMLU, ARC, HellaSwag, and TruthfulQA. These are also compiled into model leaderboards like HuggingFace’s Open LLM Leaderboard.
This is helpful for the demand side of this market:
By ranking models based on their efficiency, accuracy, and other metrics, leaderboards provide a clear, comparative snapshot of their capabilities. These then become a valuable resource for identifying which models are leading the pack in any given domain, from understanding human language to recognizing objects in images.
- Top 8 leaderboards to choose the right AI model for your task
But the problem this creates for the supply side of the LLM market is that any leadership is fleeting, lasting only until a competitor beats you on some measure, which in AI happens on a daily basis.
No sooner is a SOTA marvel of AI research and development released, than it is stripped back to a bland comparison of benchmark metrics, and appraised on a feature/price continuum.
This is rational behavior for the buyer side of the market, but it is compounded by the LLM makers themselves, who fall into the trap of offering the comparison proactively.

The Pricing Race To The Bottom
Amid the hyperbole of AI enthusiasts and hysteria of AI doomers, I’ve started to notice quite rational concerns being raised about the lack of pricing power in the API market for LLMs.
In the year since, what we’ve seen is that there doesn’t appear to be a moat in LLMs except at the highest end… At the GPT 3.5 level, however, you have many options for hosting, and you can even host it yourself. This necessarily limits the prices any company can charge.
The necessary implication is that the undifferentiated LLM market will become a ruthless competition for efficiency, with companies competing to see who can demand the lowest return on invested capital.
From The Evolution of the LLM API Market by
This also affects the consumer usage market as well:
[Meta] Making the best model in the world for free is an absolutely devastating move for all competitors which are now left trying to make money with $20/month subscriptions for models that are significantly worse and also much less known.
in his review of GPT-4o
Who Wins 76% of the Profit?
Should you be in any doubt about how significant this problem is, consider the research from Play Bigger advisors that finds that in any given tech category, just one dominant player takes 76% of all the profit from the category.
This challenges the assumptions of many people that believe a market may be big enough to sustain multiple players. In reality, the next 2-10 challenger brands they see are fighting over just 24% of the scraps.
I recently asked the authors of this study whether they expected the same scenario may play out for the LLMs, to which
expressed 100% confidence that it would.Be Radically Different, not Incrementally Better
As discussed in my recent article Category Proof In Engineering, the escape hatch from the battlefield of head-to-head competition is to avoid the default mode of comparison and actively work to be incomparable.
This starts from creating and positioning a product that is so tangibly different from competitors, that it makes no sense to compare it all. When you exist in a category of one, pricing pressure is released.
IOW, the best way to compete is not to.
LLM Positioning (Or Lack Thereof)
So how are the makers of the LLMs currently positioning them to counter these risks?
ChatGPT
In the parlance of Category Design, Open AI is the Category King. (Though I prefer to say category champion.)
You see this in the language of competitors and commentators alike when they talk of “GPT-grade quality” and in their propensity to default to Open AI as the safest bet.
Me: What language model do you use for your [enter task name here]?
AI peer: GPT-4
Me: Why? I bet a smaller model will work while being cheaper and faster
AI peer: I don’t know. I didn’t know what to choose and that was the safest bet
From
in Top 8 Leaderboards for choosing the right AI model for your taskThis level of leadership should grant Open AI a license to focus on their own advancements in communication and disregard competitors entirely. But even they fall into the trap of comparing themselves to others.
This chart from their own release of GPT-4o comparing themselves to other players may be intended to show their competitor’s inferiority, but it actually validates the competitors as being worthy of comparison.
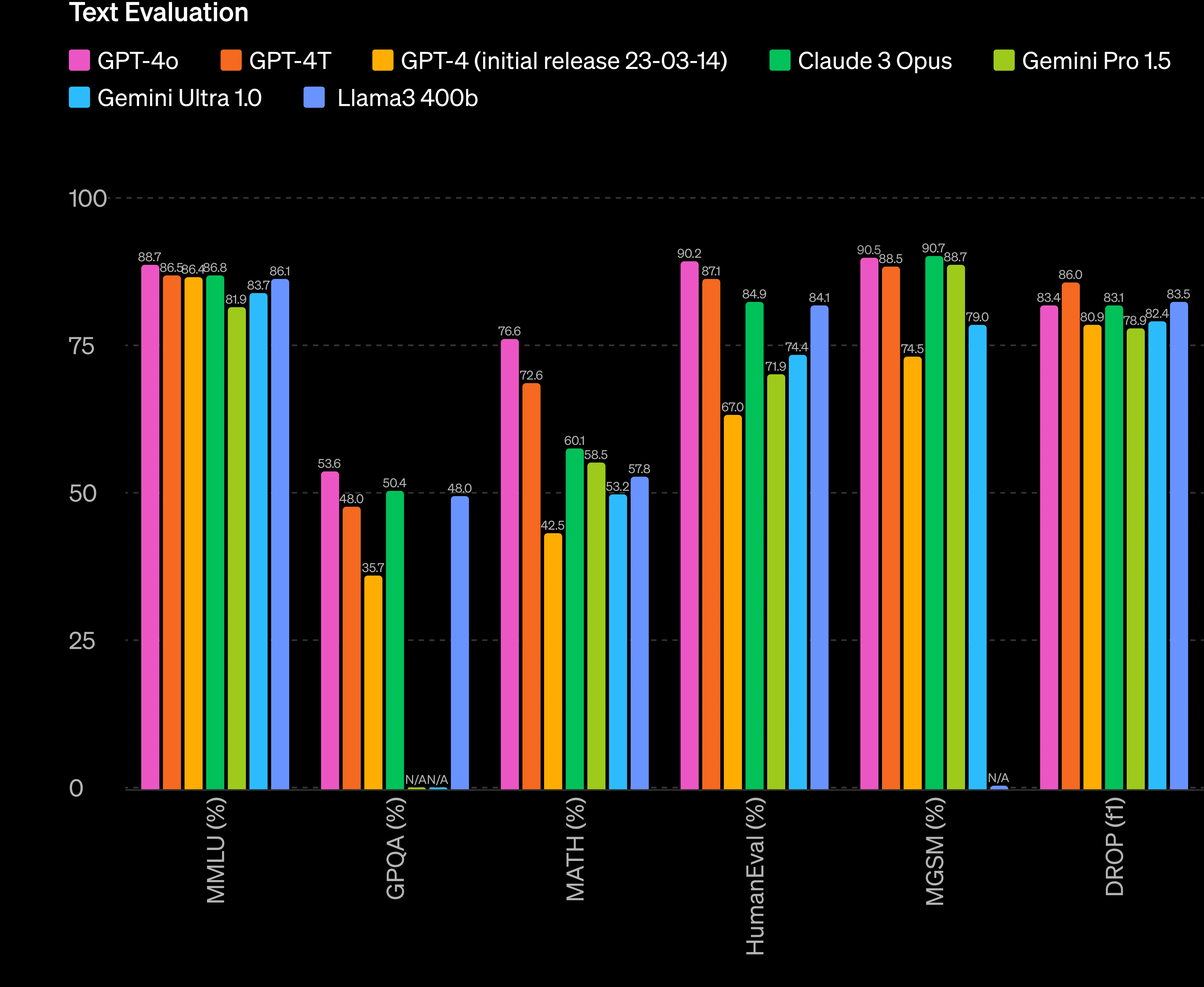
Meta AI & Llama
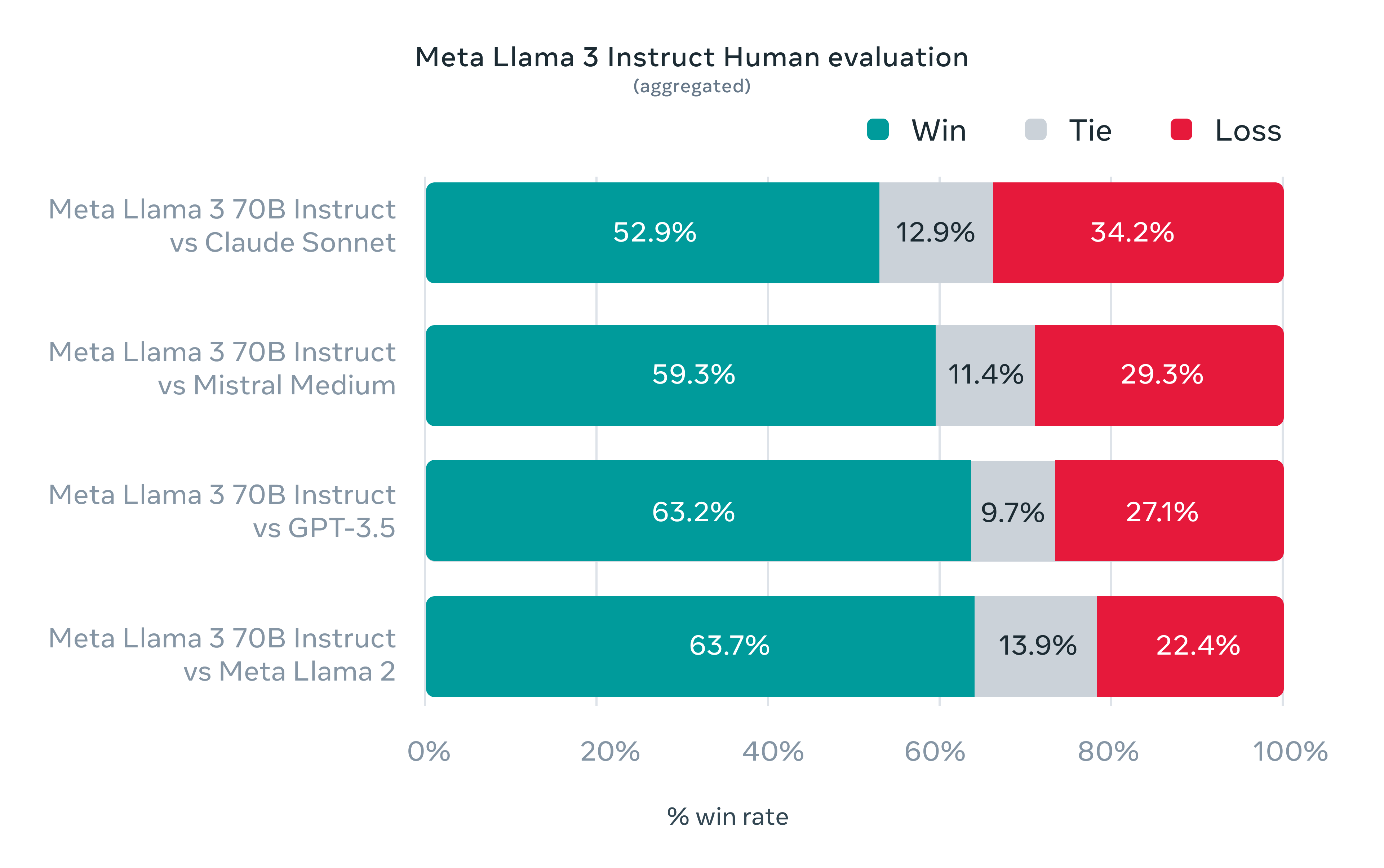
Meta describes Llama almost exclusively by how it is “better” and never by how it is different.
Meta’s own communication of Llama 3 boasts of “The most capable openly available LLM to date” and the consumer-facing Meta AI apps as “we believe Meta AI is now the most intelligent AI assistant you can use for free”
While these were probably intended as confident assertions of their excellence, they are in fact examples of “better” positioning that acknowledge the existence of competitors. Especially as they also name and compare them in their own marketing:
Google Gemini 1.5
Released just a few weeks ago, Google/Deepmind’s Gemini 1.5 is another remarkable feat of engineering, launched with the most unremarkable positioning:
“Our most flexible models yet”
Such language makes it hard to even argue that Google is playing the “better” game. It almost admits that it is not better.
Why This Matters For Your Product
Most people like to assume that the best product wins. Or if not the best product, then maybe the best team, or the deepest pockets.
This is not going well for the LLM makers, who despite having the world’s greatest resources, find themselves locked in a fierce competitive battle. If this is the case at the model level, what does it look like at the application layer where your product likely lives?
Even more competition, and even less differentiation.
Sample a few categories on There’s an AI for That and you’ll see there are, for example:
Dig deeper by exploring how competitors in these crowded spaces position themselves on Product Hunt, and you’ll find hundreds of similar products jostling with statements like:
“Generate 6 months of SEO content in 1 week”
…And thousands more just like them, identical, and devoid of any discernible positioning.
There is no way a prospective buyer could choose among so many identikit products, which means there is no way the market will be able to sustain them.
While it is hard to predict exactly how the battle at the LLM layer will play out, it is easy to predict that there will be a bloodbath for undifferentiated products at the app layer.
Spot The Differences
What saddens me about the commoditization of the LLMs is that they do actually have some very meaningful differences among them.
ChatGPT is not just a chatbot, it has an ecosystem of an app, Custom GPTs, and other benefits that become more compelling as a whole
Meta’s Llama is not just almost as good as GPT, it is the category champion of open-source AI
Mixtral is a contender in open source too, but also opens new use cases and possibilities through smaller models that are more efficient to run
When viewed at the consumer experience layer, differentiation is even more exciting:
Meta AI’s consumer AI products are integrated into the world’s most popular apps, giving them unprecedented consumer reach, and the potential to shift global usage of AI
Copilot is deeply integrated into Microsoft’s products, accelerating the penetration of AI into everyday business as usual
Gemini too could be deeply into Google’s work products, as well as into their cash cow search experience
The product differentiation is there, but even that does not overcome the gravitational pull of the market’s instinct to compare, nor the maker’s reflex to compete.
Nascent Category Champions
While most LLM makers seem intent on engaging their enemies in open battle, a few LLMs avoid the comparison trap by being categorically different and incomparable:
Grok from X.ai has tangible differences in function and use case thanks to its real-time access to X (Twitter)
Perplexity is emerging as the leader of the “Answer Engine” category.
Though both these products are technically LLMs, you never see them listed on the leaderboards. It just doesn’t seem a valid comparison - and that’s precisely the point.
Missed Opportunities
Achieving radical differentiation through category design is not just about creating a category name. Done properly it starts with identifying a unique POV, and comes full circle with engineering that POV into the product itself.
Here are some quick examples of the opportunities these giants are currently missing…
Claude & Constitutional AI
Anthropic consistently position their work as putting “Safety at the Frontier.” They even have created what sounds like a new category name of “Constitutional AI” for an objectively different approach of 'RL from AI Feedback' (RLAIF) instead of RLHF.
As a user, I enjoy using Claude more and find the writing much better than ChatGPT. Most of my friends and peers agree. So their claims of being “better” seem fair, even without the support of a league table.
The question is why? What I would love to hear from Anthropic is specifically how their POV of Constitutional AI engineered into the product is what makes it better.
Currently Anthropic misses the opportunity. They create company PR that is all about Constitutional AI, but product marketing that is just about “better” stats and features.
Gemini & Seek AI
Much has been written about Google’s existential threat from AI Answer Engines such as Perplexity. We can already see Google’s AI answers rolling out for select searches as a defensive bid.
But Google also has a unique opportunity to differentiate their LLM to API customers through understanding the search firehose itself. Much as Grok has a unique ability to see what people are tweeting about, Google has an even greater opportunity to see what people seek, whether that’s an answer, a product, an experience or anything else.
Rather than compete at Open AI’s game as yet another chatbot, or vs Perplexity as an answer engine, Google has the potential to do something very different that leans into their leadership in search.
Who cares what Gemini’s MMLU score is, if it is the ONLY product that could bring real-time search insights into an experience?
How Your Product Can Escape the Downward Price Spiral
We are currently witnessing the world’s most innovative and remarkable technologies, released at unprecedented pace by the world’s smartest people at the best-funded companies of all time.
And yet, we witness yet another commoditization of the technology and a pricing race to the bottom.
If it can happen to them, it is virtually guaranteed to happen to you. Unless, that is, you make a deliberate decision to differentiate your product to avoid competition.
Recognize that buyers have an instinct to compare, which is why every seller has an instinct to compete.
Make a conscious decision to proactively position your product away from direct comparisons and protect it from pricing pressure
Differentiate your product around a clear POV that forces a choice, not a comparison
It’s important to note that positioning is of course not the only factor influencing the commoditization and price pressures facing LLMs.
Additional forces such as compute availability and stickiness of user experience are obviously pivotal. Coincidentally just as I wrote this article, Harry Stebbings’ 20VC released a brilliant podcast episode on precisely this topic.
However, compared to the various external forces mentioned on that episode, the act of deliberately positioning yourself as radically different is far easier, and more within your control.
This means this is where you should start too.
Need Help Getting Started?
I’m working on new content and a free course to walk you through the steps needed to activate radical differentiation. To be notified when available, and get a link to free office hours chat with with me, become a free subscriber of this publication here.
Great write-up! One other leaderboard I'll add to the mix is RewardBench [0]. Extremely useful for deciding which model to use for automated evaluation.
[0] https://huggingface.co/spaces/allenai/reward-bench